EREIGNISSE SEIT 1.12.15
Am Freitag den 15.Januar 2016 hatten Tobias und ich das erste gemeinsame Treffen nach dem Experiment No.1. Zwischenzeitlich gab es ja am 12.12.15 das Experiment No.1b, das ich alleine bestreiten musste, da Tobias auf Europatournee war. Am 3.Januar 16 hatte ich dann schon mal eine erste Nachreflexion zu Experiment No.1+1b eingeschoben.
RICHTUNG
Die Frage war, wo wir stehen, wo wir hinwollen, und wie.
Ein Orientierungspunkt war das Bekenntnis zum offenen Klangraum. Dahinter wollten wir auf keinen Fall zurück.
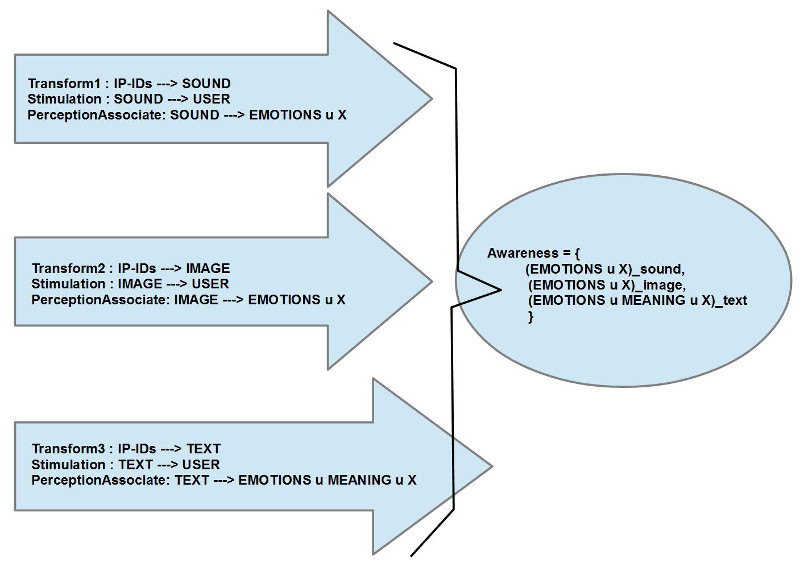
Zugleich war klar, dass das Performance-Format PHILOSOPHY-IN-CONCERT auch ein Bekenntnis zur Kommunikation ist, zu einer Botschaft, zum Kerngeschäft von Philosophie und Wissenschaft, zu einer künstlerischen Vermittlung von diesen Inhalten.
Daraus folgt ganz klar, dass wir neben dem allgemeinen Sound auch immer und wesentlich bedeutungsassoziierenden Sound haben müssen, gesprochene Sprache.
Die Reflexionen vom 3.Januar zum angenehmen Klang lassen anklingen, was alles involviert sein kann.
Nach einigen gedanklichen Kurven war klar, dass die Komposition von bedeutungsfreiem und bedeutungsassoziierenden Klang nicht das Abgleiten in gefällige Mainstreammuster beinhalten sollte. Wahre Kunst braucht einen minimalen Grad an Originalität, Kreativität, Innovation, um dem Andruck der Zukunft Raum zu geben. Dies geht normalerweise nicht ohne ein Minimum an Nicht-Gefälligkeit einher, ein Minimum an Reibung und Aufwand von Neuem. Rattenfänger erkennt man daran, dass sie maximal gefällig sind (oder sie haben so viel Macht, dass sie alles radikal autoritär durchzusetzen versuchen).
ERSTE GEDANKEN
Für das nächst Konzert wollen wir dann ernst machen mit der Einbeziehung der Maschinendimension.
In den Sciencefiction Romanen und Filmen, in den Massenmedien unserer Zeit, werden intelligente Maschinen seltsam verklärt, geradezu mystisch überhöht wie in einer neuen Weltreligion. Roboter, Computer, intelligente Algorithmen der Zukunft können nicht nur alles, sie können es selbstverständlich auch viel besser als wir, die Menschen. Erklärungen dafür liefert bislang niemand. Selbst in den Hochglanzdokumentationen von Arte findet man nur schöne Bilder, keine wirklichen Fragen, keine wirklichen Erklärungen, null Problembewusstsein. Sektenmitglieder der neuen Weltreligion ‚die intelligente Maschine‘ könnten es möglicherweise nicht besser machen: Ist dies staatlich finanzierte Propaganda des Unsinns?
Für das Experiment No.2 werden wir beginnen, reale Dialoge mit den Maschinen als Teil der Performance einzubauen. Keine Fakes. Wir werden es einfach tun, und dann im Anschluss darüber mit den Teilnehmern des Abends darüber diskutieren: Was ist passiert? Was haben wir gemacht? Wie ist dies möglich? kann es noch besser sein? Wo liegen die Unterschiede zwischen Menschen und Maschinen, wo die Ähnlichkeiten? Sind wir nicht letztlich auch nur Maschinen?
ORTE UND TERMINE
Wir suchen ab 21.1.16 aktiv nach einem möglichen Aufführungsort; im Moment denken wir an ein Kunst- oder Technikmuseum mit interessanten Räumen. Sobald wir den Raum haben, werden wir den Termin festlegen. Da wir unser PHILOSOPHY-IN-CONCERT Projekt als einen Prozess verstehen, machen wir nicht erst ein neues Konzept und suchen dann den Termin, sondern wir suchen uns einen öffentlichen Anlass, auf den hin wir unsere künstlerischen Aktivitäten ausrichten. Was immer wir inszenieren, es hat seinen Sinn niemals nur ‚in sich‘, sondern in dem kommunikativen Ereignis des Aufzeigens, Aufnehmens und diskursiven Verdauens.